Technology services
Technology services
Reengineering
The savings that can be achieved with an XML content management system will typically not be realized without reengineering. One or more of the following areas should be considered in a reengineering effort:

- PROCESS — Automation based on content eliminates entry steps and associated proofreading. Database workflow tracking eliminates the need for most manual production control. Single sourcing the data avoids the conversion steps most publishers go through to deliver information online.
- ORGANIZATION — Often organizations are set up to support legacy processes or systems and have many functions which are redundant or unnecessary. Streamlining the Organization not only reduces the time and money it takes to produce a product, it often reduces errors and improves content quality. When "by rote" tasks are eliminated your staff is able to focus on content rather than process which makes them more effective. Reducing the number of people that a process must pass through reduces bottlenecks. Shorter time to market (minutes rather than hours or days) can eliminate competition in highly competitive markets.
- DATA — Many implementations of new systems do nothing more than replace one tagging method with another. While this does give access to parsers and other XML compliant tools, it is not enough. When converting data for a project all of the future uses of the data should be considered (e.g. repurposing for new products). In an Online world where only fragments of data may be delivered, the data has to be able to stand alone without the surrounding print context. Tagging content below the paragraph level (e.g. people, subjects, items, and references) provides rich searching or automation of finding aids.
- TECHNOLOGY — Often a technology appears to work perfectly well for a task but holds you back. An example might be a desktop publishing application (DTP) that produces pages that look wonderful. What is not obvious is that DTP requires special expertise, which requires more people in the process, which causes more handoffs of the data, which causes more delays in the process. This type of workflow might mean that a web product has to wait for days while desktop re-composes an entire volume, when a simple change could have been delivered to the web as soon as it was written and approved.

Data Analysis
Companies that benefit from content management are typically managing large volumes of data or data with a long life cycle. Most historical data is tagged with only enough information to insure it "looks right". While this is fine for producing a one time print product, it has very little additional benefits. Tenebral Technology performs data analysis that goes beyond how something formats. We typically search for:
- Additional embedded content that can be used for finding aids or advanced searches
- Common data that occurs in many places which can be shared
- Opportunities to remove all formatting from content
- Topical information that can be used for alternate Taxonomies or alternate navigation aids
- Cross references, embedded references, and subject references that may be links in a future electronic product
- Stand-alone subject groups. Often used for repurposing data.
When we analyze data we consider the current use as well as the future uses of the data. Publishers that ignore this depth of analysis often end up re-converting their data for new products or systems in the future. This is an expensive process that should never be done more than once.
Our staff has performed document analysis on hundreds of print products and millions of records of online data. We bring a depth of experience to the process that insures the analysis will be done quickly and accurately. Our experience with delivery to multiple output formats and using multiple delivery mechanisms gives us insight into what works and what fails.
We use many off-the-shelf tools and our own in-house
tools to interrogate existing data. This insures we do not miss
content or rare inconsistencies in the data. These tools are designed
to work with legacy data in its best and worst form.

System Integration
Tenebral Technology provides expert integration services for Publishers. Our staff has experience creating automated publishing systems since 1983. This long history in the publishing business insures that the correct vendors and products are selected for each unique situation. It is rare that "one size fits all" when it comes to tools. More often your staff skill level or legacy system experience will determine which tool suits your project best.
System integration can range from simply installing software all the way through a complex project involving analysis of staffing, tools, data, and workflow; data conversion; typesetting development; training, and future planning
Existing Tools
We believe that off-the-shelf technology should be used whenever reasonable, and that development time is best spent creating a seamless interface between the best of breed tools. We do not believe that developing custom software for each situation is a cost effective method for publishing system implementation.
Train existing staff
Tenebral Technology is typically used to supplement our clients staff to insure that the system is implemented on time and is immediately productive. In those cases, we prefer our post-implementation training to include: why a certain technology was chosen; what the alternatives were; and what could still be added to the system. This insures that the in-house development staff continues productive enhancements as the customer's needs change. Our goal is to insure as much knowledge transfer as possible.
Broad experience
Tenebral Technology has created systems involving the following:
- Fully automated batch composition
- Interactive layout systems
- SGML and XML editing tools
- Data translation tools for both XML and non-XML data
- Data validation tools (XML and SGML parsing tools)
- Interface with legacy authoring systems
- Interface with legacy Database and indexed file systems
- Real time web serving of data from unified databases
We work with your staff to determine the most cost
effective amount of integration services needed for a given project.
Click HERE for current price list.

Data Conversion
Our staff has been converting data to SGML and XML for more than 20 years. Our focus on publishing systems has brought us a wide range of experience with many different types of data. We provide:
- Fast turnaround so you can be up and running quickly
- Dedicated resources. You will always be dealing with the same
person who will be familiar with your data.
- Experienced advice. When we see future uses for your data or
opportunities to identify detailed content or link references we will
point these out.
- Libraries of conversion patterns. We have probably encountered
data like yours in the past and can use existing conversion libraries to
save time and money
- Customer training. We can work in conjunction with your
staff and/or train them how to do the work.
- Alternatives. In a few cases it makes more sense to use
content specialists to identify content. Typically this involves reading
and understanding the material to provide additional metadata such as
keywords and index terms. We have worked with custom taxonomies and
helped our customers create their own.
We have managed small to large projects from the least expensive through large mission-critical projects involving staff in many locations. Contact us for a free data evaluation.
Custom Programming
Tenebral Technology has extensive experience developing custom applications. Our staff's programming experience ranges from 12 years to more than 25 years programming for our senior staff members. Our staff can develop custom applications for you or supplement your staff in critical situations. All of the systems we have built are successful. Technology solutions included:
- Languages: C, C++, Java, Specialized XML tools, 3GL and 4GL UI
and forms builders, scripting languages, and many typesetting languages.
- Architecture: .net/MFC, PFC, Swing, Application servers,
Client applications, n-tier applications, Applets and Servlets.
- Platforms: Windows, Solaris, Unix, Linux, VMS, and Mainframes.
Technology
Our staff does not recommend a single technology solution. The old adage that "A man with a hammer sees every problem as a nail" all too often applies to our industry. More often the issue of deployment or performance will dictate that one technology can or cannot be used.
For example, 3-tier C and C++ applications are often more work to program and deploy, but for certain bandwidth limited or complex interface situations they cannot be equaled for performance. On the other hand, a distributed Java application can be easier to program and maintain and may have more future uses if programmed in a services model. We work with our clients to understand thier current and future needs before making a technology decision.
Database Programming
We specialize in large database repository applications. We understand what it takes to design and implement an application which utilizes a heterogeneous mix of text and legacy data. We provide the performance, reliability, and scalability that our customers have come to expect from enterprise Oracle applications.
Our designers also understand the needs of end users and consistently design elegant User Interfaces which are easy to understand while still providing advanced features and performance. The special requirements of complex text searching has been an industry problem that we have many decades experience solving.
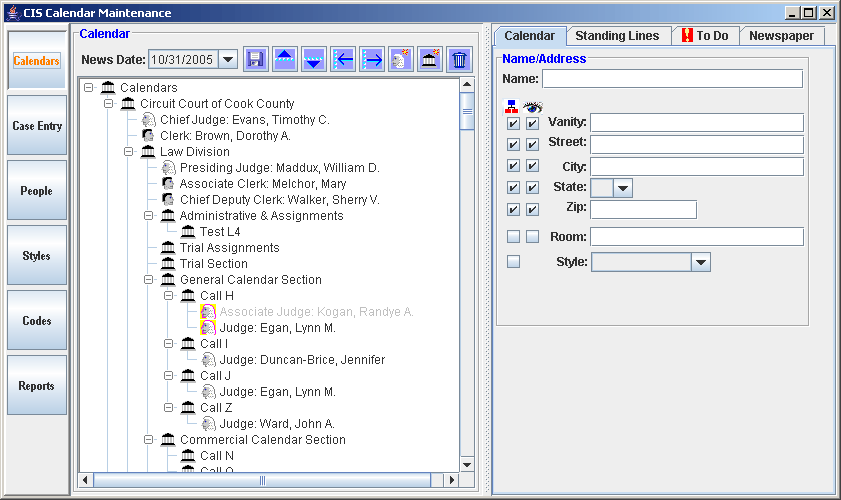
Below is an example of a custom C++ application that was written for an online subscription service. The product provides the ability to search for Jury Verdict cases by over 4000 different keyword terms in 32 categories. All of the data is stored in the SPM XML repository and the complex user interface was created to make it easy for users to create complex searches without having to know XML search logic or Boolean rules.
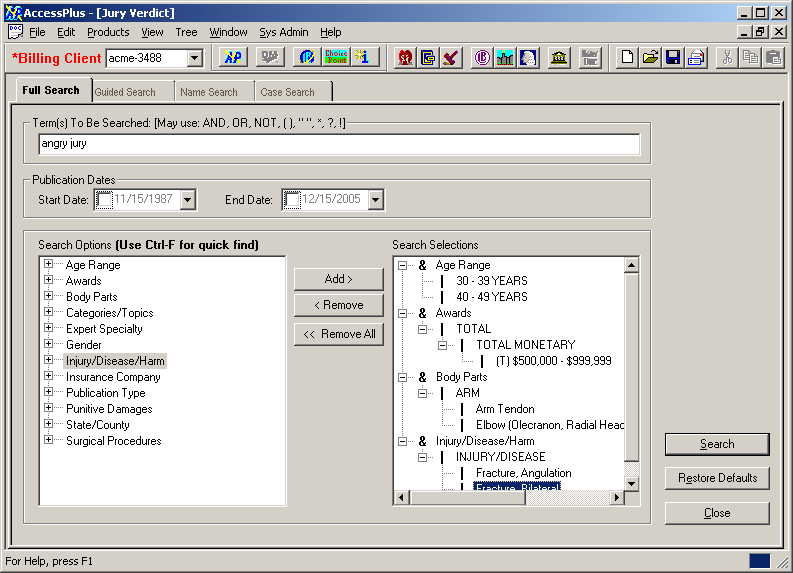
Below is an example of a custom Java Swing input application. This was designed to be easily deployable as an application or applet. The end result of this application is a complex XML document, but the data is initially stored as relational fields to insure normalization across many legacy and other non-XML systems in use at the customers site. Another consideration for this design was the users that would be performing most of the maintenance. The users were accustomed to traditional input systems, not XML tools, because most had started their careers in the 1980's using terminal input systems. The interface can be used with little or no mouse input because of the extrensive use of keyboard shortcuts. Great attention was spent to the Swing implementation details to insure a responsive User Interface